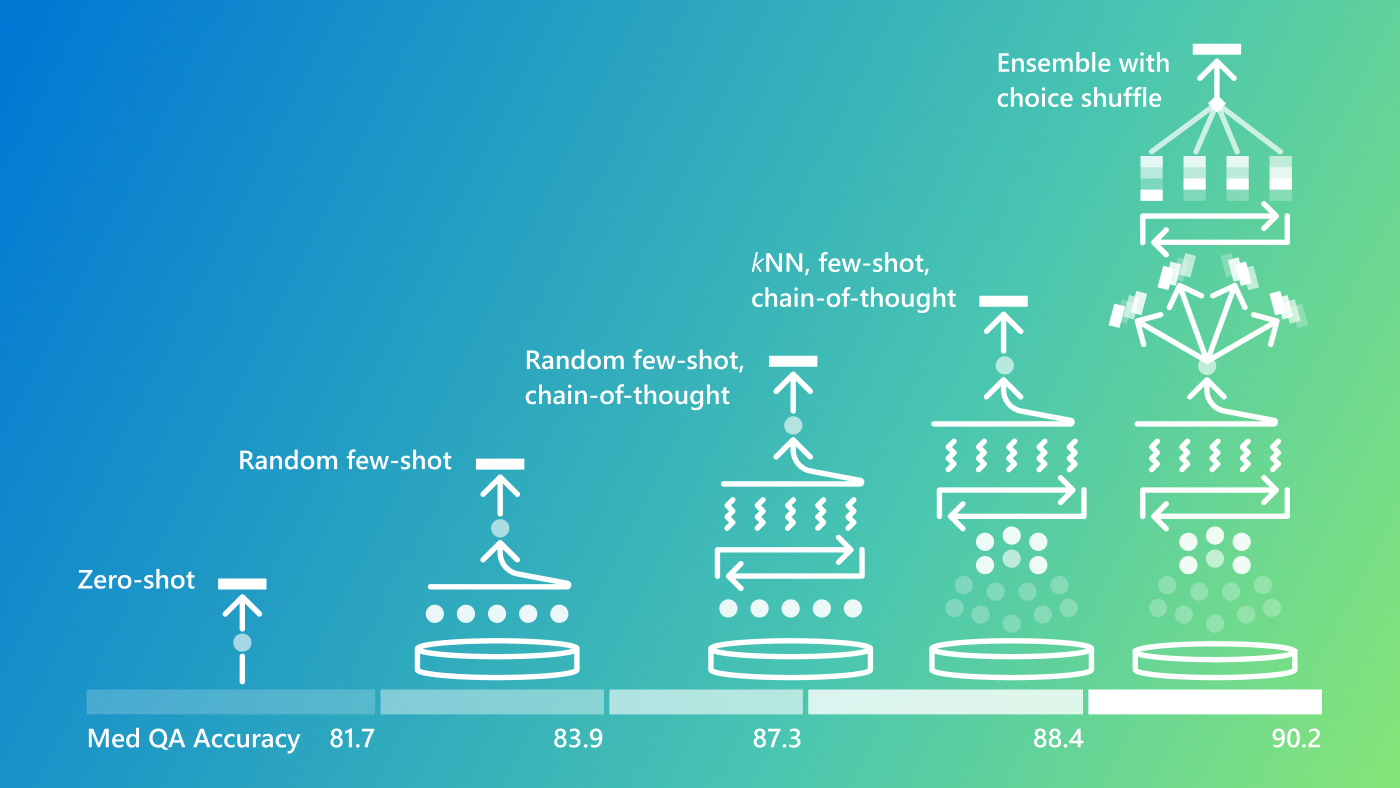
Groundbreaking advancements in frontier language models are progressing rapidly, paving the way for boosts in accuracy and reliability of generalist models, making them highly effective in specialized domains. As part of our ongoing exploration of foundation model capabilities, we developed Medprompt last year—a novel approach to maximize model performance on specialized domain and tasks without fine-tuning. By leveraging multiphase prompting, Medprompt optimizes inference by identifying the most effective chain-of-thought (CoT) examples at run time and drawing on multiple calls to refine output. When deployed with GPT-4, Medprompt achieved an impressive 90.2% accuracy on the MedQA benchmark (USMLE-style), outperforming all other methods.

Less than a year later, our tests show the OpenAI o1-preview demonstrated superior performance over Medprompt, reaching 96% on the same benchmark (Figure 1)—without using sophisticated prompt guidance and control. This advancement is driven by the model’s integration of run-time strategies at its core, enabling state-of-the-art results on medical licensing exams in the United States and Japan, medical subsets of the Massive Multitask Language Understanding (MMLU) benchmark, and nursing exams (NCLEX) as shown in Figure 2.

These results are notable, prompting us to publish our recent study, findings, and analyses, From Medprompt to o1: Exploration of Run-Time Strategies for Medical Challenge Problems and Beyond (opens in new tab). But the numbers are only part of the story. In this blog, we discuss prompting strategies to make the most of o1-preview models and other factors to consider as well as directions forward for run-time strategies.
Is o1-preview “just” fancy prompting?
The introduction of the OpenAI o1 model series marks a significant shift from prior GPT models. Unlike GPT, o1 models are trained using reinforcement learning (RL) techniques that enable them to “think” before generating outputs. While Medprompt relies on a cascade of operations with GPT-4 at run time guided by a multistage prompt, the o1 series incorporates this run-time reasoning directly into its RL-based design. The built-in functionality enables the o1 models to significantly outperform even the best results using GPT-4 and Medprompt. The performance gains come with a notable tradeoff: its per-token cost was approximately six times that of GPT-4o at the time of our evaluation. While the results for GPT-4o with Medprompt fall short of o1-preview model performance, the combination offers a more cost-effective alternative. The cost-benefit tradeoffs are highlighted in the following figure, with the x-axis presented on a logarithmic scale.

Can we prompt engineer o1-preview?
The o1-preview model exhibits distinct run-time behaviors compared to the GPT series. While some of our more dynamic prompting strategies performed better than expected with o1-preview models, our most tried-and-true strategy was anything but consistent throughout our evaluation. Figure 4 captures specific performance results for Tailored Prompt, Ensembling, and Few-Shot Prompting on o1-preview. Here’s a summary of our findings:
- Tailored Prompt: While minimal prompting—like a brief, one-sentence description followed by a question—offered a strong baseline performance, detailed task descriptions were best for eliciting accurate responses.
- Ensembling: Generating multiple answers per question and using majority voting across different reasoning paths boosted reliability, while shuffling answers in runs produced richer reasoning chains and improved outcomes. Ensembling continues to yield consistent performance improvements.
- Few-Shot Prompting: Guiding the model with a few examples produced inconsistent results and, on average, decreased performance compared with GPT models.

Spotlight: Blog post

Research Focus: Week of September 9, 2024
Investigating vulnerabilities in LLMs; A novel total-duration-aware (TDA) duration model for text-to-speech (TTS); Generative expert metric system through iterative prompt priming; Integrity protection in 5G fronthaul networks.
Do results stand in another language?

We expanded our research to include a new multilingual benchmark based on the Japanese national medical licensing exam. The JMLE (Japanese Medical Licensing Examination) is written in Japanese and administered in February 2024, after the o1-preview model’s knowledge cutoff. Even without translation to English, the o1-preview model achieved a remarkable score of 98.2% accuracy (Figure 5), well above the exam’s minimum passing score of approximately 80%.
Do reasoning tokens improve performance?
For fun, we conducted tests to determine whether increasing the number of reasoning tokens could improve performance. Our findings showed that by adjusting the prompt, we were able to consistently increase the number of reasoning tokens used by o1-preview, and the increase was directly correlated with improved performance as demonstrated in Figure 6.

What’s the takeaway?
Bottom line: There’s a little something for everyone when it comes to run-time strategies. We’re excited by the performance gains from GPT models to o1-preview models. While these improvements are significant, so is the cost. For those needing proven accuracy on a budget, Medprompt leveraging calls to GPT-4 is a viable option for medicine and beyond. We summarize the relative performance of prompting strategies in Figure 7 to determine the best option, or check out the paper for a detailed breakdown of every dataset, experimental configuration, and prompt template (opens in new tab).

Anything more to consider?
We highlighted several considerations in the paper that are worth checking out. Here are three opportunities that are top of mind:
- Research on run-time strategies. The research community has largely relied on boosting model capabilities with data, compute, and model size, predictably achieving gains by way of scaling laws. A promising new direction is inference-time scaling—the value of investing in additional computation and machinery for guiding inference at run time. We highlight in the paper opportunities to guide run-time allocations to boost efficiency, accuracy, and intellectual capabilities, including meta reasoning and reflection in real time and learning during the “idle” time (opens in new tab) between problem solving. We see a great deal of opportunity for new research and development on real-time and “offline” reasoning, learning, and reflection.
- Benchmark saturation. With the rapid advancement of state-of-the-art models, many existing medical benchmarks are reaching “saturation,” where models perform extremely well on standing medical competency challenges, considered extremely difficult just a few years ago. Current benchmarks, such as USMLE and JMLE, were designed to assess the performance of medical students and clinicians and are increasingly inadequate for evaluating cutting-edge AI models. To drive understandings of models and guide research, we need to design more challenging medical benchmarks.
- From benchmarks to clinical applications. We note that, while benchmarks offer valuable insights into performance and accuracy, they often fail to capture the complexities and nuances of real-world clinical decision making and healthcare delivery, more broadly. Conducting clinical trials to rigorously evaluate the impact of AI applications on patient care poses far greater difficulties than benchmarking models against challenge problems drawn from medical competency exams. Yet, studies of AI deployments in realistic clinical settings are essential for understanding model capabilities and for guiding the effective integration of AI into healthcare.
Resources
- From Medprompt to o1: Exploration of Run-Time Strategies for Medical Challenge Problems and Beyond (opens in new tab)
- Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
- The Power of Prompting
- Steering at the Frontier: Extending the Power of Prompting
- Capabilities of GPT-4 on Medical Challenge Problems (opens in new tab)
The post Advances in run-time strategies for next-generation foundation models appeared first on Microsoft Research.