Loading
Editor’s note: This post is part of the AI Decoded series, which demystifies AI by making the technology more accessible, and showcases new hardware, software, tools and accelerations for GeForce RTX PC and NVIDIA RTX workstation users.
From games and content creation apps to software development and productivity tools, AI is increasingly being integrated into applications to enhance user experiences and boost efficiency.
Those efficiency boosts extend to everyday tasks, like web browsing. Brave, a privacy-focused web browser, recently launched a smart AI assistant called Leo AI that, in addition to providing search results, helps users summarize articles and videos, surface insights from documents, answer questions and more.
Leo AI helps users summarize articles and videos, surface insights from documents, answer questions and more.
The technology behind Brave and other AI-powered tools is a combination of hardware, libraries and ecosystem software that’s optimized for the unique needs of AI.
NVIDIA GPUs power the world’s AI, whether running in the data center or on a local PC. They contain Tensor Cores, which are specifically designed to accelerate AI applications like Leo AI through massively parallel number crunching — rapidly processing the huge number of calculations needed for AI simultaneously, rather than doing them one at a time.
But great hardware only matters if applications can make efficient use of it. The software running on top of GPUs is just as critical for delivering the fastest, most responsive AI experience.
The first layer is the AI inference library, which acts like a translator that takes requests for common AI tasks and converts them to specific instructions for the hardware to run. Popular inference libraries include NVIDIA TensorRT, Microsoft’s DirectML and the one used by Brave and Leo AI via Ollama, called llama.cpp.
Llama.cpp is an open-source library and framework. Through CUDA — the NVIDIA software application programming interface that enables developers to optimize for GeForce RTX and NVIDIA RTX GPUs — provides Tensor Core acceleration for hundreds of models, including popular large language models (LLMs) like Gemma, Llama 3, Mistral and Phi.
On top of the inference library, applications often use a local inference server to simplify integration. The inference server handles tasks like downloading and configuring specific AI models so that the application doesn’t have to.
Ollama is an open-source project that sits on top of llama.cpp and provides access to the library’s features. It supports an ecosystem of applications that deliver local AI capabilities. Across the entire technology stack, NVIDIA works to optimize tools like Ollama for NVIDIA hardware to deliver faster, more responsive AI experiences on RTX.
NVIDIA’s focus on optimization spans the entire technology stack — from hardware to system software to the inference libraries and tools that enable applications to deliver faster, more responsive AI experiences on RTX.
Brave’s Leo AI can run in the cloud or locally on a PC through Ollama.
There are many benefits to processing inference using a local model. By not sending prompts to an outside server for processing, the experience is private and always available. For instance, Brave users can get help with their finances or medical questions without sending anything to the cloud. Running locally also eliminates the need to pay for unrestricted cloud access. With Ollama, users can take advantage of a wider variety of open-source models than most hosted services, which often support only one or two varieties of the same AI model.
Users can also interact with models that have different specializations, such as bilingual models, compact-sized models, code generation models and more.
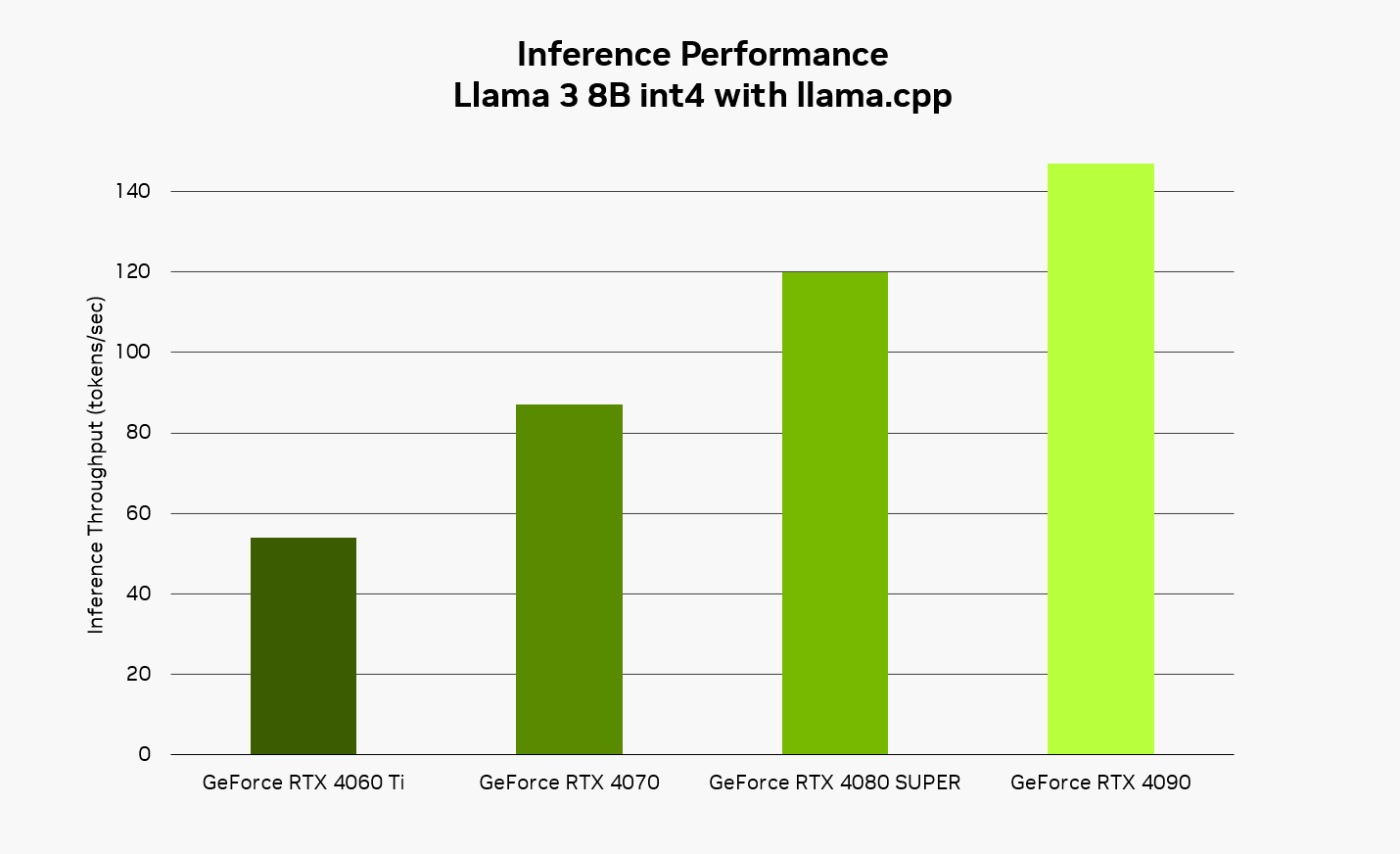
RTX enables a fast, responsive experience when running AI locally. Using the Llama 3 8B model with llama.cpp, users can expect responses up to 149 tokens per second — or approximately 110 words per second. When using Brave with Leo AI and Ollama, this means snappier responses to questions, requests for content summaries and more.
NVIDIA internal throughput performance measurements on NVIDIA GeForce RTX GPUs, featuring a Llama 3 8B model with an input sequence length of 100 tokens, generating 100 tokens.
Installing Ollama is easy — download the installer from the project’s website and let it run in the background. From a command prompt, users can download and install a wide variety of supported models, then interact with the local model from the command line.
For simple instructions on how to add local LLM support via Ollama, read the company’s blog. Once configured to point to Ollama, Leo AI will use the locally hosted LLM for prompts and queries. Users can also switch between cloud and local models at any time.
Brave with Leo AI running on Ollama and accelerated by RTX is a great way to get more out of your browsing experience. You can even summarize and ask questions about AI Decoded blogs!
Developers can learn more about how to use Ollama and llama.cpp in the NVIDIA Technical Blog.
Generative AI is transforming gaming, videoconferencing and interactive experiences of all kinds. Make sense of what’s new and what’s next by subscribing to the AI Decoded newsletter.
{kind=link}
{kind=link}
{kind=link}